
Introduction
You're looking for a text-to-speech tool. Perhaps for your business telephone messages. Perhaps to understand how to choose the right solution from all those available on the market. Maybe because you've heard of AI voices and want to assess whether they can really be used in a professional context.
This guide answers all these questions. We cover what TTS really is, how it works, in what contexts it is applied, and above all why consumer tools do not meet the same needs as those designed for corporate telephony, a widespread but surprisingly undocumented use.
If your need is immediate, you can create your first professional voice message for free on Voconix in under 30 seconds, with 25 voices and over 10,000 tunes. If you prefer to understand the subject in depth first, the rest is for you.
1. Definition and history: how TTS went from the laboratory to the invisible world
The definition
Text-to-speech (TTS) is the technology that converts written text into audible speech. From a text input, it produces an audio file that can be read on any device, integrated into an application, broadcast on a website or loaded into a telephone system.
This is the opposite of speech-to-text recognition, which works in the opposite direction, from speech to text.
The result is an audio file (MP3, WAV, OGG depending on usage). The question is no longer «Does it work? but »Is the quality good enough for my purposes? And the answer, for some years now, has been yes in almost all professional cases.
Sixty years of evolution in four major stages
Text-to-speech was not born with AI. Its history dates back to the middle of the 20th century, and is a perfect illustration of how a technology evolves from a laboratory gadget to an invisible, everyday infrastructure.
1950s-1970s: physical synthesizers. The first TTS systems were electronic machines that attempted to reproduce the physical mechanisms of the human voice: vibrations of the vocal cords, resonances of the oral cavity, articulations. The result was immediately recognisable as artificial. A robotic, flat, lifeless voice, more reminiscent of science fiction than real communication.
1980-2000: synthesis by concatenation. A fundamentally different approach is required: instead of simulating the voice, a human being is recorded pronouncing thousands of isolated syllables and words, then assembled to form any sentence. This is a quantum leap in quality. This was the technology that powered the first talking GPS units and automatic messaging systems. But the joins between sounds are still sometimes perceptible, and intonation is often mechanical.
2000-2015: statistical modelling. Approaches such as HMM (Hidden Markov Models) make it possible to model the human voice statistically and generate a more fluid synthesis. The voice sounds more natural on short sentences, but remains recognisable on long or complex texts.
Since 2016: the neural revolution. WaveNet, developed by Google DeepMind in 2016, marks a clear breakthrough. This deep neural network learns directly from human recordings to generate sound waves, sample by sample. For the first time, synthetic voices regularly deceive human listeners in blind tests. Subsequent models (Tacotron, FastSpeech, VALL-E) will continue on this trajectory, right up to today's voices that can narrate a text with credible emotional nuances.
This is the level of quality that professional TTS tools such as Voconix offer today: neural voices that sound natural, without the mechanical aspect of previous generations.

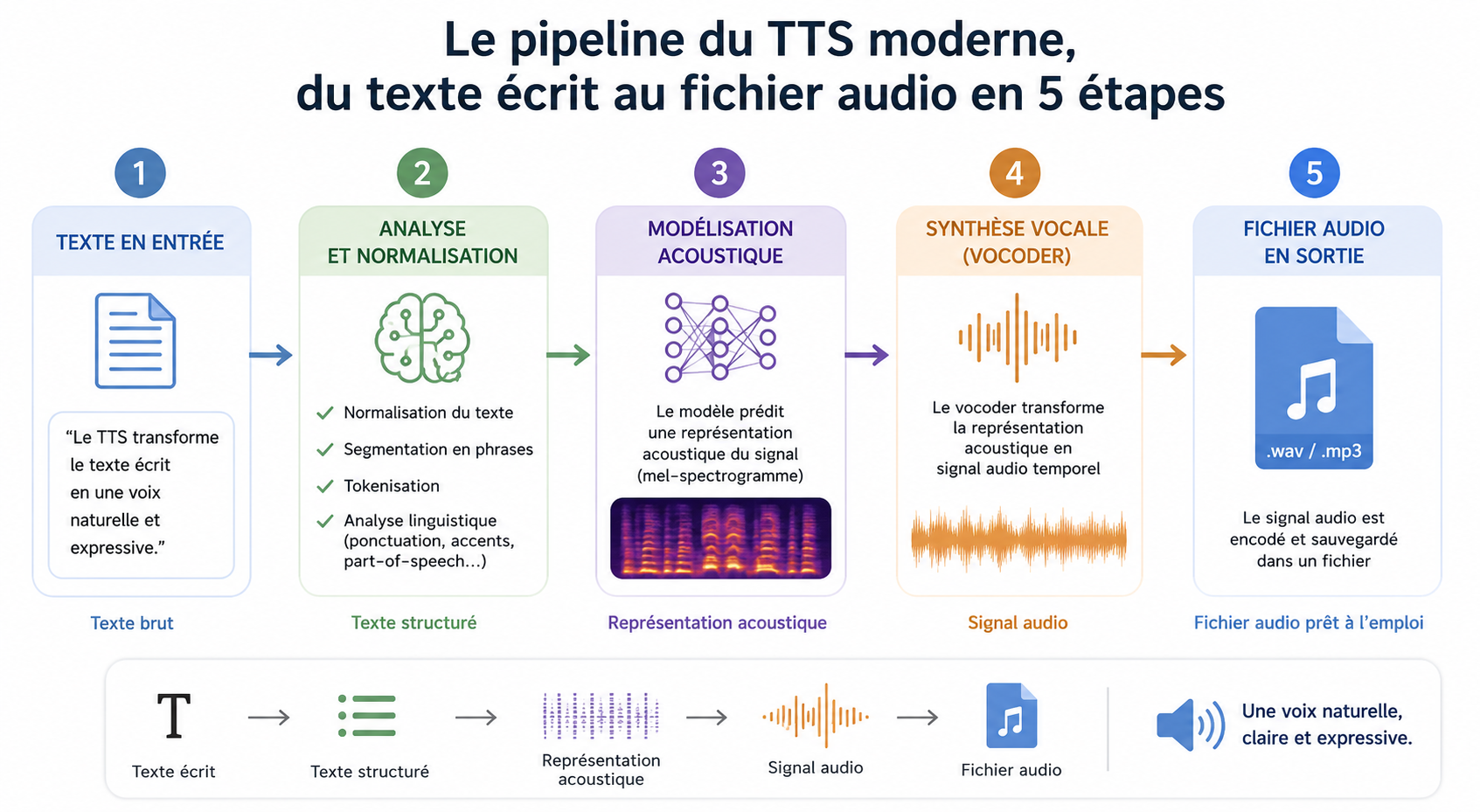
2. How does modern TTS work? Technology explained simply
Understanding how TTS works explains why some tools are better than others, and why some contexts of use are more demanding than others.
Stage 1: analysing the text, understanding before speaking
The first phase of TTS does not produce any sound. It consists of understand the text, which is much more complex than it seems.
A human reading aloud automatically resolves hundreds of ambiguities without realising it. A TTS system has to resolve them explicitly.
Homographs. The word «son» is pronounced differently depending on whether it refers to children or fishing line. The correct pronunciation depends on the context, which the system must be able to analyse.
Figures and numbers. «15 March» should read «fifteen March». «1,500» should read «one thousand five hundred euros». «05 57 22 92 10» should be read digit by digit. Each digital format has its own rules for reading, and an error in a business message is immediately obvious.
Acronyms. «SNCF» is pronounced letter by letter. «NASA» is pronounced like a word. A good TTS system distinguishes between these cases using complex rules and databases of special cases.
Punctuation and prosody. A comma implies a slight pause and a particular inflection. A question mark changes the melodic contour of the sentence. Punctuation is a score that the human reader reads intuitively, and that the TTS must learn to interpret.
The best TTS systems use natural language processing (NLP) models to resolve these ambiguities before producing any sound. Voconix also incorporates a memorising difficult pronunciations You correct the pronunciation of a proper name or an atypical term once, and it is retained permanently for all your messages.
Stage 2: the phonemic sequence, breaking language down into elementary sounds
Once the text has been analysed, the system converts it into a sequence of phonemes, These are the basic sound units of the language. French has around 36 distinct phonemes. «Bonjour» can be broken down into /b/, /ɔ̃/, /ʒ/, /uʁ/.
This transcription is enriched with prosodic information: where to place the accents, how to modulate the duration of each sound, what pitch variations to adopt to make the phrase sound natural.
Stage 3: Speech generation, from phonemes to sound waves
A neural model trained on hundreds of thousands of hours of human voice recordings takes the phonemic sequence as input and generates the acoustic characteristics of the voice. A component called a vocoder converts these characteristics into an audible sound wave.
The whole process takes place in a few tens of milliseconds. The resulting audio file is ready to use.
What distinguishes good TTS from bad
La size and diversity of training data A model trained on 100,000 hours of diverse human speech will be intrinsically better than a model trained on 1,000 hours of a single voice.
La long-term context management The best models adapt their intonation according to the meaning of the whole sentence, not word by word.
La natural prosody the art of placing pauses, accents and variations in rhythm in the right places. This is the criterion most immediately perceptible to the ear.
La robustness in difficult situations These include proper nouns, technical terms and mixed languages. A good TTS handles these cases without flinching.
3. The main uses of text-to-speech
TTS is applied in very different contexts, with constraints specific to each use. Understanding these differences is essential to choosing the right tool.
Accessibility: the original vocation
Before being a productivity tool, the TTS was, and remains, a fundamental accessibility tool. For visually impaired people, dyslexics or those with cognitive problems affecting reading, it represents a gateway to the world of the written word. A screen reader that voices a web page, an application that reads incoming messages: these are uses where TTS plays a role in real inclusion.
Creating audio and video content
Content creators (YouTubers, podcasters, online trainers, marketing teams) use TTS to narrate videos without recording their voice, or to quickly localise content in several languages. This market has exploded with the rise in quality of AI voices.
E-learning and vocational training
E-learning incorporates TTS on a massive scale to generate module narratives without having to hire an actor for each content update. In this context, consistency over time is crucial: a course of 50 modules must sound homogeneous, even if the modules are produced over several months.
Voice assistants and conversational agents
Siri, Google Assistant, Alexa: they all use TTS to answer aloud. Voice AI agents for call centres use very low latency TTS systems for real-time conversations.
Embedded and IoT
GPS, station announcements, interactive terminals, industrial warning systems: TTS embedded in physical devices responds to radically different constraints from cloud uses (lightness of the model, offline operation, robustness in noisy environments).
Business telephony: the most widespread use in companies
It is the most widespread use in the business world, and paradoxically one of the least documented. Hundreds of thousands of French companies use TTS on a daily basis for their professional voice messages, without necessarily knowing it or putting it that way.
Every time a caller hears a welcome message, a IVR menu, a voice announcing a waiting time or a professional answering machine, There's a good chance that it's a synthetic voice. It is so common that it has become transparent.
This use deserves a development of its own, so technically and operationally different is it from other use cases. This is precisely the core of what Voconix offers.
4. TTS in business telephony: why it's a world apart
What generalist tools can't handle
When you generate a voice-over for a video, the audio format doesn't matter: a standard MP3 works everywhere. Professional telephony is a world with its own technical rules, its own legal constraints and its own operational logic.
The audio format is the first invisible constraint.
Professional telephone systems (IPBXs such as 3CX or Mitel, traditional PABXs or cloud solutions such as Aircall or Ringover) do not accept just any audio file. Each system has its own specifications:
| Type of system | Expected format | Frequency | Encoding |
|---|---|---|---|
| Classic PSTN / PABX | WAV mono | 8,000 Hz | µ-law or A-law |
| Modern VoIP IPBX | WAV mono | 8,000 or 16,000 Hz | 16-bit PCM |
| Cloud solutions | Variable | Often more flexible | MP3 or WAV depending on the platform |
A WAV file generated at 44,100 Hz (standard CD quality) imported into an IPBX configured for 8,000 Hz will either be rejected or played back with a distorted voice. Your telecom installer will then have to intervene to convert the file manually, with the delays that this implies.
Accurate pronunciation is a functional requirement.
In a telephone greeting, it's the first word the caller hears, and it's often the name of the company. Rough pronunciation creates an impression of carelessness in the first few seconds. Telephone numbers, opening hours, proper names: these are all cases where a non-specialised TTS can be disappointing.
A telephone message is never a naked voice.
It is mixed with background music. This mix of voice and music complies with precise rules (the music must be 12 to 18 dB below the level of the voice), and the music used must be free of rights for professional telephony in France (SACEM and SCPA regulations).
A company manages a fleet of messages, not a single file.
It has an average of ten messages: welcome message, answering machine, IVR menus, waiting message, voicemail These messages must be consistent with each other (same voice, same musical universe, same sound level) and updated regularly.
Delivery to the installer is the last mile, often forgotten.
Setting up a new message generally involves the telecoms installer. Without automatic notification, this process can take hours or days, which is problematic when an urgent closure has to be announced the same evening.
Voconix has been designed to meet all these requirements in a single tool.
Audio format adapted to your IPBX, memorised pronunciation,
catalogue of 10,000 royalty-free music tracks,
manage your entire fleet of messages, and
automatic delivery to your telecom installer.
5. AI voice vs. human voice: which should you choose for your messages?
This is one of the most frequently asked questions when it comes to professional TTS. The answer: it all depends on the message.
What the AI voice does better
Speed. A modified message (a schedule, a date, a new collaborator) is generated in 30 seconds, without a recording session.
Consistency over time. An AI voice is available identically today and in three years' time, with no variation in timbre or quality.
The volume. When a company has 40 employees, each with a voicemail to create, or when a network of franchises has to deploy the same message in 150 establishments with local customisations, AI voice is the only economically and operationally viable solution.
Multilingualism. Voconix allows you to produce messages in French, English, Spanish, German and Italian with native voices for each language, in a single tool.
The cost. The cost of a quality TTS-generated voice message is a fraction of the cost of a studio recording with a professional actor.
What the human voice does best
The complex emotional register. For an important institutional message, a talented actor brings an emotional dimension that the best TTS still reproduce imperfectly.
Absolute uniqueness. A real human voice, with its slight imperfections and uniqueness, can become a real signature sound, recognisable and memorable.
Creative interpretation. An actor interprets a brief. The TTS, however excellent, follows rules: it doesn't act.
The right approach: combining the two depending on the message
Pour l’immense majorité des messages téléphoniques d’entreprise (accueil standard, IVR menus, boîtes vocales des collaborateurs), la voix IA de qualité est non seulement suffisante, elle est préférable pour ses avantages opérationnels. Pour certains messages à haute valeur symbolique, la voix humaine garde sa place.
Voconix offers both options: 25 voices available, AI and human, so you can choose according to the message, the desired register and your budget.
Listen to our voices on your own texts before committing yourself.
25 voices in 5 languages, available as a free trial. No credit card required.
Free trial
6. How do you choose your TTS tool for business telephony?
If you need to create or update your business telephone messages, here are the questions to ask yourself before choosing.
Is the output format compatible with your telephone system? Ask your installer exactly what format he can import into your IPBX (sampling frequency, encoding, mono or stereo). Format incompatibility leads to either rejection or degraded sound. Voconix automatically generates formats adapted to each type of system.
Does the tool offer high-quality native French voices? Test with your own texts, particularly those containing proper nouns, figures and professional wording specific to your sector.
Is the music integrated and legally usable? A business telephone message without music loses perceived quality. Check that the music offered is royalty-free for use in professional telephony in France. Voconix includes over 10,000 royalty-free music tracks with automatic voice and music mixing.
Does the tool manage a fleet of messages over time? Message history, organisation by employee or by site, voice consistency over several years: these are essential functions for a company, which are absent from most generalist tools.
Is delivery to the installer automated? Without automatic notification, each update requires manual transmission of the file. Voconix automatically notifies your installer as soon as a new message is ready.
Voconix meets all these criteria.
Create, manage and distribute your professional voice messages completely independently.
Discover our rates · Try it for free
7. TTS and the ethical issues you need to know about
A comprehensive guide to TTS cannot ignore the ethical issues raised by this technology.
Voice cloning: powerful and regulated
The best TTS technologies now make it possible to create a vocal clone of a person from just a few minutes of recording. Used legitimately (for example, to preserve the voice of someone suffering from a degenerative disease), this is a remarkable advance.
Used without consent, it is a serious violation of human rights. Serious platforms impose strict mechanisms: the person concerned must explicitly consent, and detection systems identify unauthorised clones.
For companies: if you create a «branded voice» based on a real human voice, make sure that the person has signed an explicit agreement covering commercial use and the desired duration of use.
Audio deepfakes: a real threat
With the current quality of AI voices, it is technically possible to create very realistic audio recordings of a person saying things they never said. This is a growing threat to confidence in voice authentication systems and to the reputation of public figures. The answer lies in the development of detection technologies, regulation and increased vigilance.
The impact on the voice industry
The market for professional voice actors has been directly affected by the rise in quality of TTS. The sector is adapting, with debates over voice image rights and cloning contracts, but the transformation is real.
8. The future of TTS: where is the technology heading?
Virtually zero latency. The best current systems generate speech with a latency of 75 to 300 ms. Research is aimed at getting the latency below 50 ms to make AI voice agents indistinguishable from a human in a conversation.
Controllable emotional expression. The most recent models already allow emotions to be injected directly into the text. This granularity will be refined to the point where it will be possible to fully direct an actor without recording a single second of sound.
Voice personalisation as a brand asset. Companies will treat their voice in the same way as they treat their logo: as an asset to be built, protected and used across all their contact points, including the telephone.
Integration into conversational AI agents. TTS will become a fundamental building block for voice agents that combine natural language understanding, conversational memory and voice output in a continuous, natural flow.
Transparent multilingual management. Future models will make it possible to switch from one language to another in the same message, with the same voice, with no break in quality. What is today a technical exercise will become a basic functionality.
Conclusion
In sixty years, text-to-speech has come a long way, from the first electronic synthesizers to today's neural voices that deceive the human ear. For companies, the question is no longer «Is TTS good enough? The answer is yes in the vast majority of professional cases.
The real question is «What tool, for what purpose, with what guarantees?» For business telephony, this means a solution that understands the technical constraints of IPBXs, integrates voice and music into a single workflow, manages the consistency of your messages over time, and automates delivery to your installer.
Voconix is that solution.
Create your professional voice messages in 30 seconds, with 25 voices, over 10,000 royalty-free music tracks, in 5 languages, with automatic delivery to your installer.
Try it for free · See offers and rates
9. How to create your text-to-speech voice message with Voconix
Text-to-speech is a technology, but using it doesn't have to be. Here's how Voconix transforms plain text into a professional voice message ready to drop on your switchboard.
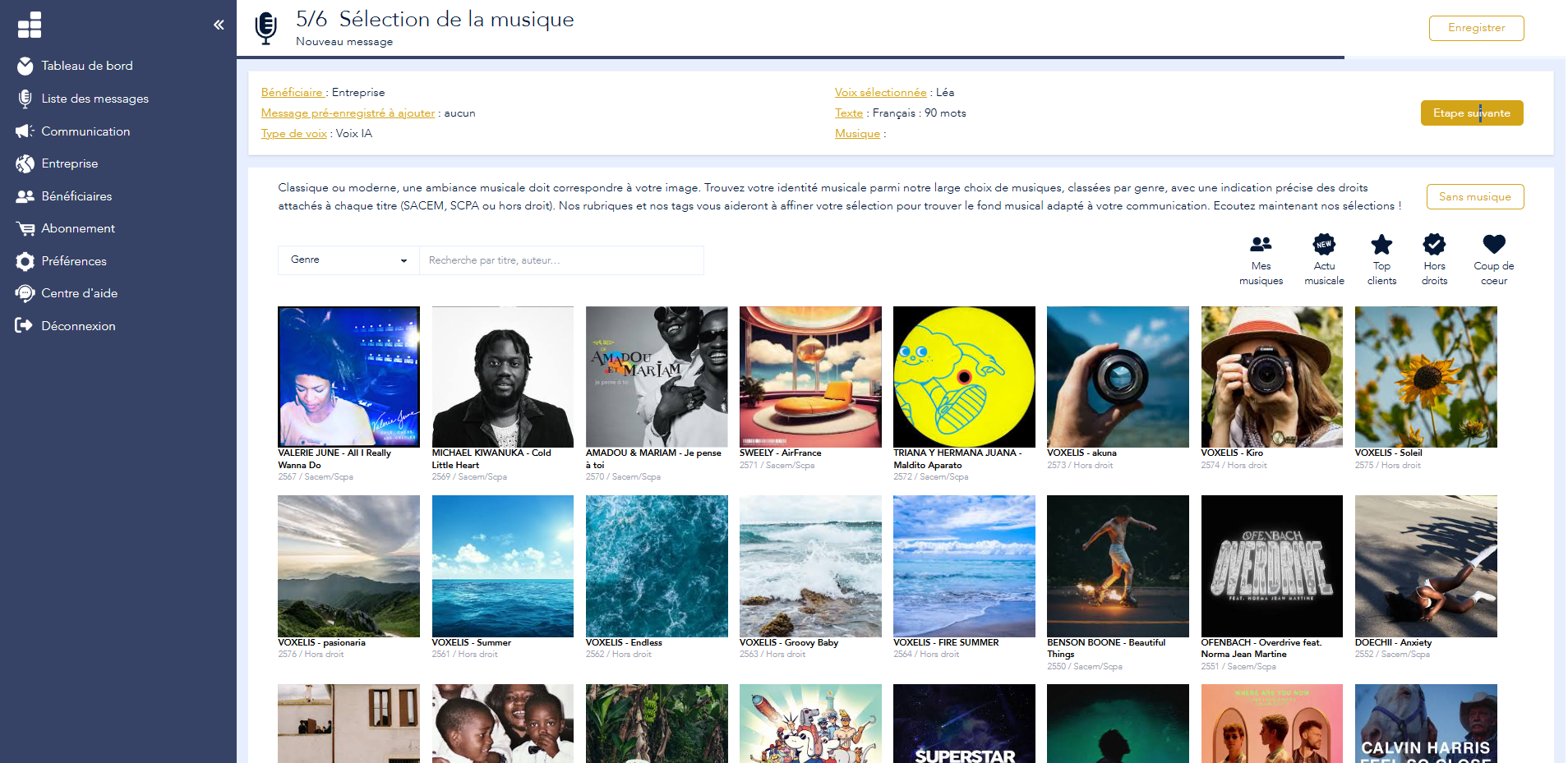
Type or paste your message into Voconix. Pre-written templates are available for every situation: reception, answering machine, IVR, waiting, closure, holidays.
25 AI and human voices in 5 languages. Optionally add music from over 10,000 royalty-free titles. Automatic mixing included.
MP3 or WAV file compatible with your IPBX, or automatic notification from your telecom installer. No additional conversion.
Try it now. The player at the top of this page is the real Voconix tool. Type your text, choose a voice and listen to the result.
Create your first message for free See prices10. Examples of ready-to-use text-to-speech voice messages
These templates can be used directly in Voconix. Copy, paste into the player, choose a voice and listen in 10 seconds.
«Hello, you've reached [Company name]. Our advisors are available Monday to Friday from 9am to 6pm. If you have any queries, please write to us at contact@[domain].fr. See you soon.»
Create this message →«Hello, you've reached [First name Last name]. I am currently unavailable. Please leave your name, number and the subject of your call and I'll call you back as soon as possible.»
Create this message →«Thank you for calling. All our advisers are currently on the line. Your call is important to us. We will get back to you in a few moments.»
Create this message →«Welcome to [Company]. For sales, press 1. For technical, press 2. For accounting, press 3. To speak to an advisor, press 0.»
Create this message →«Hello, due to an exceptional closure today, our offices are closed. We will resume on [date] at [time]. You can write to us at contact@[domain].fr.»
Create this message →«Hello and thank you for calling [Company]. Your call will be answered in a few moments. An advisor will get back to you shortly.»
Create this message →«Hello, the [Company] team is on holiday from [date] to [date]. We will be back on [date] and will deal with your messages as soon as we return.»
Create this message →«Bonjour, vous êtes bien chez [Entreprise] / Hello, you've reached [Company]. Pour le français, tapz 1 / For English, press 2.»
Create this message →These models are starting points. Voconix offers pre-written scripts for each situation directly in the tool.
Create your first message for free See prices